

In data engineering, I’m not interested in fetching one particular call. Instead, I aim first to get incremental data every day/hour/minute or get all historical data from collections that I’m interested in, known as backfill.
Of course, every API provider is different, and we need to look into the documentation to see how to use it. After integrating a few dozen APIs, I’ve noticed some similarities. When integrating with a data source using a REST API, you typically have two types of endpoints. The first type provides the current state of a collection, similar to a dimension table with fewer entities, many updates, and fewer inserts. The second type can be a time-range one, usually a transactional type of collection, with many inserts and few or no updates. In this article, we'll focus on fetching data from paginated APIs.
How It Usually Works
You get the API endpoint, for example, /orders, and you will have some parameters to fill in like account, date_from, and date_to, either in a GET or POST request. The response will likely look something like this:
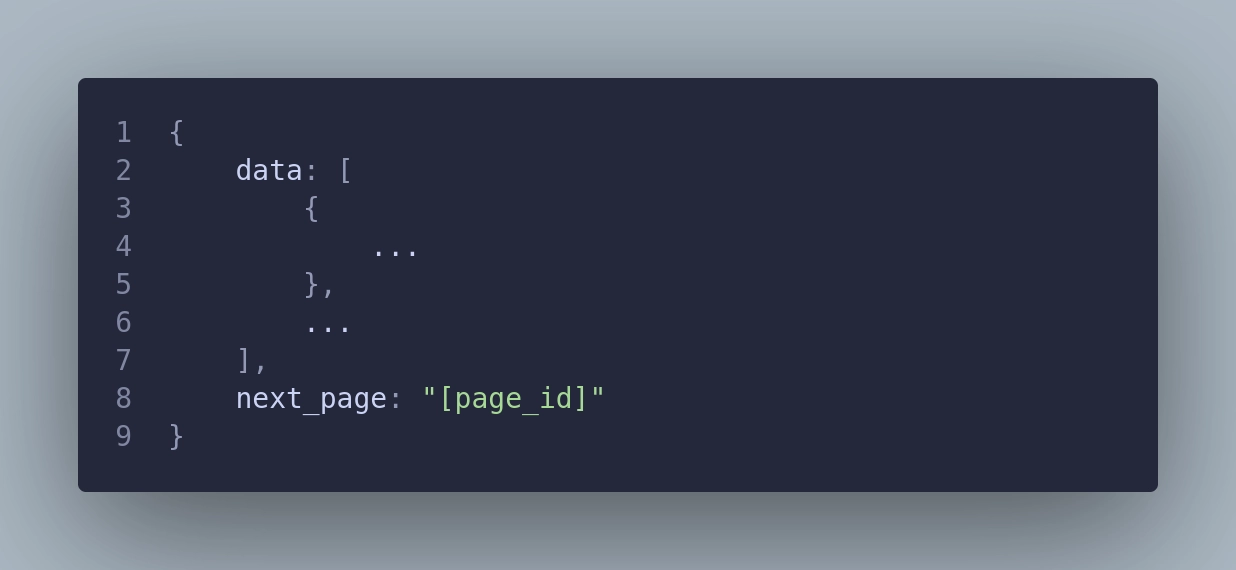
As you can see, we can split the response into two parts. The first part is the data itself – the list of structures from /orders collection provided in the data field. Each structure represents one document from the collection that we are pulling data from. The second part is metadata, which is not related to the collection itself but rather to fetching data from the API. In this example, we have the next_page field. This is usually the case with APIs, where data is paginated. This mechanism protects the provider's server from too much traffic. You can get, for example, 100 rows per call and then make another call for the next page. You continue to make API calls until there is no next field available in the response. This means that you have retrieved all pages from your query.
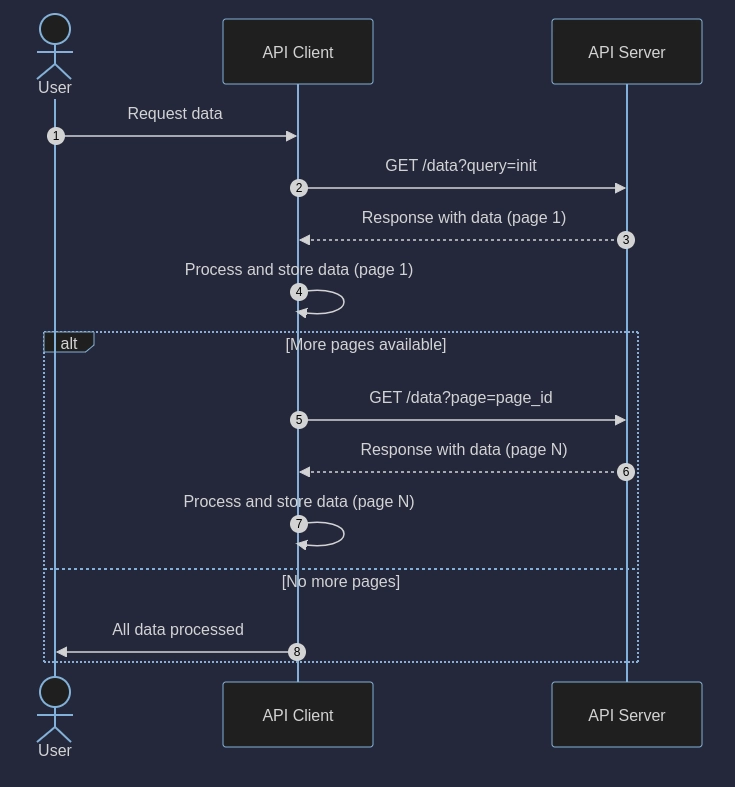
Level 1: Naive Approach
So, this is the idea. Get the first response, collect the rows from data, and append data from the next page until no more pages are available. Easy, right?
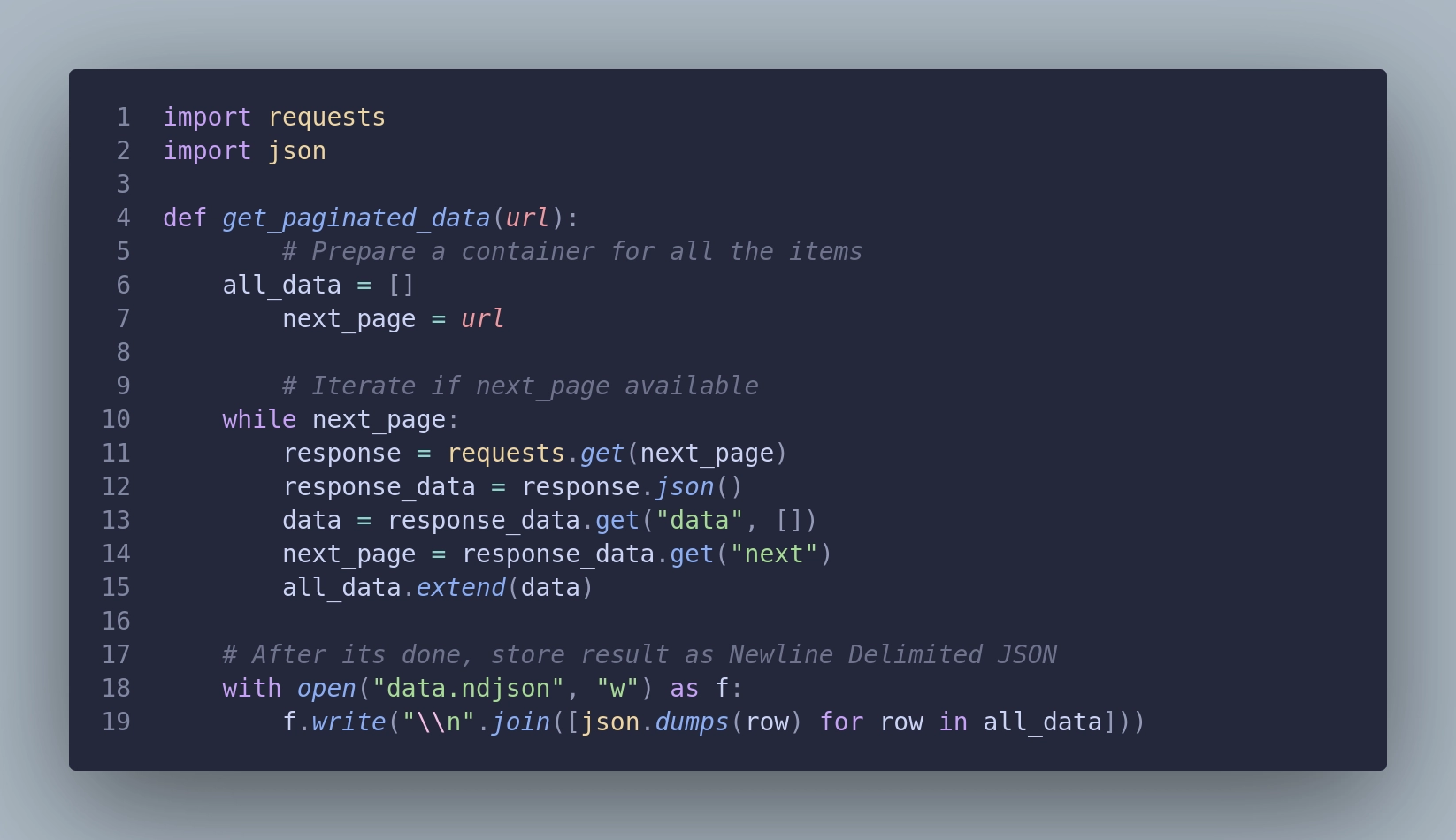
This solution however has a major flaw. What will happen if, in the middle of collecting data, one of the responses will raise an error?
Level 2: Preventing Data Loss
To improve this a little, let's capture a failure. This happens often when working with REST APIs. We are sending and receiving tons of requests and responses, so there's a high chance that at least one will fail. To prevent losing all data that was successfully fetched, let's implement a mechanism that will gracefully stop the fetching session and store the data that was already collected. Look at the api_call function.
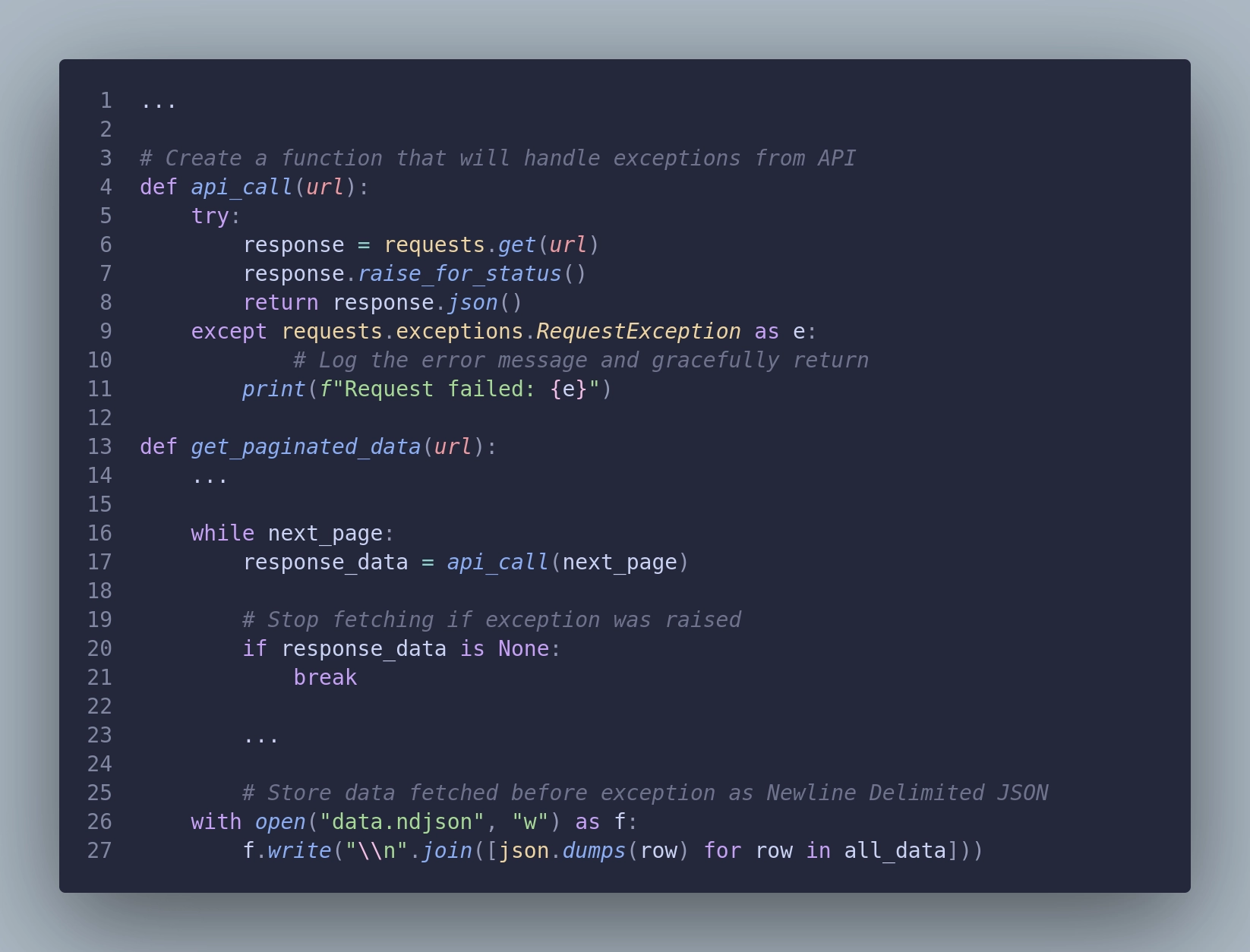
That’s better. Now, when we will run a long fetching session we can preserve what we already fetched, so we don’t need to run it again on error. This is especially useful when you need to pay for every api call, to limit the overall costs.
Level 3: Writing to a Temp File
Our approach can work, but there are a few problems with keeping data in memory. Most important, what happens if we run out of memory on our machine? Fetching data from HTML is not a highly demanding task for machines, so you will probably want to use small machines to be cost-effective.
Let’s handle data sizes bigger than memory. To achieve this, we can store data in a file. This way, every piece of data from the response will be stored on the disk. This has two advantages. We free up memory, and all responses will be kept if the session breaks, so we don’t lose data that was already collected.
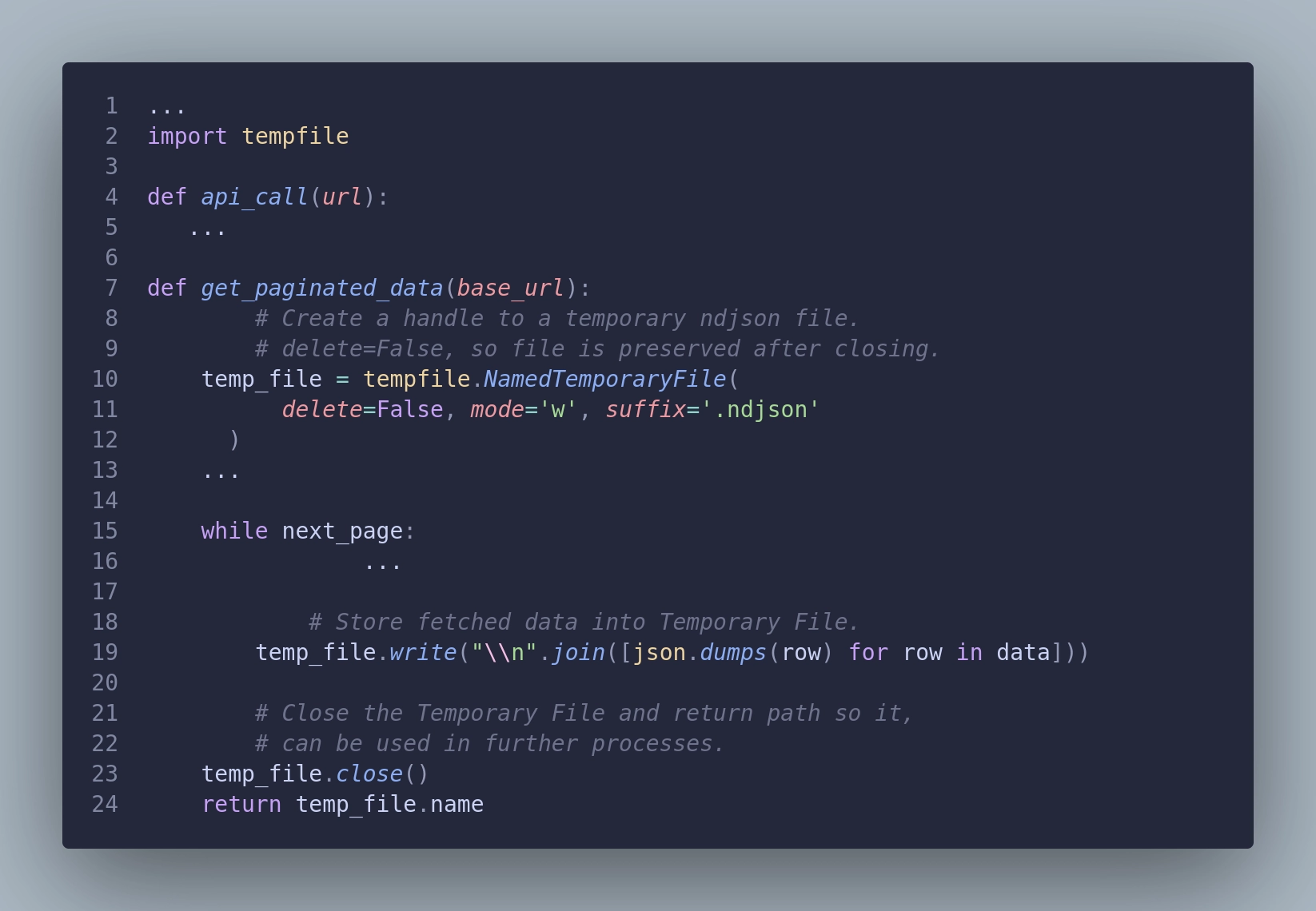
This solution is better and more robust than previous ones, but it still has one big disadvantage. It will generate a lot of I/O operations, which are expensive and will slow down our operation. Can we do better?
Level 4: Buffered Temp File
Another step in our ladder is to add an in-memory buffer of a fixed size. This way, we combine the advantages of the first and third levels, with the ability to tweak our fetching application to our taste. We will create a list to collect the data (buffer) from many responses and store data (flush) into the file when a certain condition is met. For example, we can store every 10th response. We can also have a condition based on elapsed time, like 1 minute, or the size of the batch, like 1 MB of data. How we implement this is up to us. This solution is a compromise, limiting the I/O operations but risking more data loss if an error occurs. We need to remember an edge case here: store the last bit of data when the flush condition cannot be met, but no next page is available. This might look something like this:
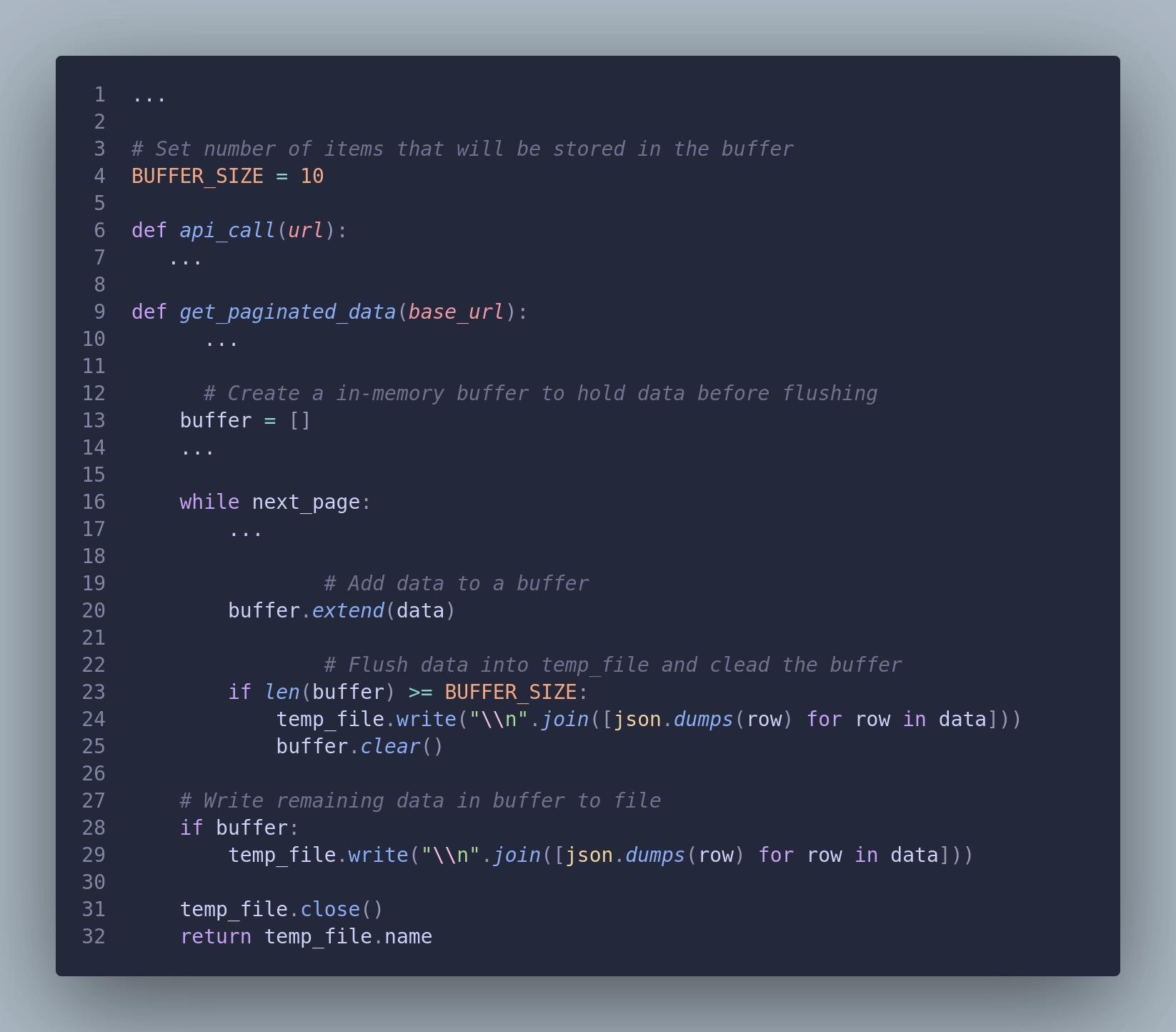
Alright! This gives us some control over the process speed and memory usage. The bigger BUFFER_SIZE the faster the process should be, but on the other hand, it will increase the data kept in memory, therefore increasing memory usage and the risk of losing some fetched data.
Level 5: Continuing Lost Sessions
The problem with API responses is that they are maintained by a third-party provider. This means we cannot assume anything about the data we receive unless it is clearly stated in the documentation. Many APIs are not deterministic; responses for queries are generated dynamically, so the sorting of data can differ, and page order can vary. The only way to ensure we get all the data we expect is to start a paginated session and get to the end of it.
There are some recovery strategies that we can implement:
- Retry: This is easy; we can just add a retry on every API call with a cool-down parameter to prevent losing an unfinished session. This method is easy to implement but can stop the application for a while.
- Stateful Recovery: Using this strategy, we can log the request and response of every call we make to the API. This way, we should be able to pick up a broken session and instead of starting from the beginning, start from the failed request. This gives us more flexibility and observability over our extractions but may not work for some APIs. If a paginated query has a session ID attached to it, the session can just expire—forcing us to start from the beginning.
- Date Range: Someone might say, “Okay, let’s say we are getting data for a whole year, we collect some data, and then fail. Let’s get the first and last date of the data we got, and start a new query session from the last timestamp we obtained.” This seems reasonable, but it will only work if the API provider guarantees that data in the responses will be sorted. As I mentioned, this is not always the case. So please be careful when using this strategy. I do not recommend it because I don’t trust third-party providers.
What About Multithreading?
It's nearly impossible to speed up the extraction of a single paginated session using multithreading. Why is that? We cannot make another call until we get the response from the previous one because we need to obtain a page ID. In many cases, query sessions are not paginated using integers like page=1, page=2, etc., but using page hashes that look something like page=ab1f7eca802befg1. The only reasonable way to multithread extraction is to multithread sessions, but multithreading one session is not possible this way.
Always be smart about it though; if your source API uses a page number that you can know in advance, go for it. It's just not true for all APIs. This is one of the reasons why fetching data efficiently and quickly is challenging nowadays.
Best case scenario? When from the first API call you get information about all pages (or item count), and page IDs are known from the first response. This way you can multithread calls to all pages at once, and collect the parts asynchronously.
Other Challenges
What will happen when data changes in the provider's database while we are fetching our session, you ask? Good question. It depends on the provider. Provider could just respond with an error that data changed and refused to continuing our session. Page ID changes and we just need to start from the beginning. This is why using a relatively small partition for the session is usually a smart option. We want to minimize the lost cost when something goes wrong, so keep that in mind.
Server internal problems are another thing that we need to handle, but we cannot do anything about this. Sometimes there is a problem internally in the API provider and the server responds with a 500 error. In this case, we need to track responses, and parts that weren't successfully fetched, to retry them later, when the server will be up and running again.
JSON format is changing itself. I can write another article about the pros and cons of JSON format, but let's limit for now to this. JSON is a schema-less, semi-structured format that has low entropy and can be deeply nested. This is not the Data Engineer’s wet dream… Especially not the most efficient format to transmit data in bulk. But sometimes you need to do, what you need to do, right? Before going strictly to REST API try to find alternatives. Sometimes there is a GraphQL endpoint, that can handle bulk queries. Sometimes you can “request” a data export pipeline. This will generate a separate link. Under this link, you can download all the data that you want in one bulk response. Sometimes you can even specify a format, CSV, Parquet, Avro, or protobuf.
Data can be changed historically. You want to expect that API calls will be deterministic. Nothing is more misleading. Data can change historically. For example, you download yesterday's partition. If you download the same partition in a couple of days, data can differ. This is a historic data change. Some APIs will give you an “updated_at” field, so you can always get the latest version of a row, but sometimes you don’t. In this case, you may want to introduce a moving window strategy instead of daily batches, to give yourself a limit of some fixed days that you will try to get the most recent data.
What to Remember about Fetching Data from Paginated APIs
- Error Handling: APIs often fail; handle errors with retries and logging.
- Memory Management: Avoid memory issues by writing data to temp files.
- Efficiency: Use buffered writes to balance memory use and I/O.
- Session Continuity: Implement strategies for recovering interrupted sessions.
- API Variability: Always adapt to each API's unique quirks and limitations.






