

Data Quality in Engineering
Validate Early, Validate Often
In data engineering, the principle of "validate early, validate often" emphasizes the importance of integrating validation checks throughout the entire data pipeline process rather than deferring them to the final stages. This approach ensures that issues are detected and addressed as soon as they arise, minimizing the risk of propagating errors through the pipeline and reducing the cost and effort required to fix them.
This is also in line with the 1:10:100 rule, based on the research of G. Loabovitz and Y. Chang, which states that:
- The cost of preventing poor data quality at source is $1 per record.
- The cost of remediation after it is created is $10 per record.
- The cost of failure (i.e. doing nothing) is $100 per record.
But what are we actually testing in our data pipelines?
What to Test?
At a very high level, we can distinguish two main areas of testing:
- Transformations - code that can be defined using Python or SQL for example.
- Data - the output of the source system or the result of our transformations.
Transformations
Most Common Mistakes
As correctly mentioned here, programming data transformations is a minefield of stupid mistakes. Here are some examples:
- Trying to access a column that’s missing from the table produced by the upstream step in the pipeline.
- Trying to access a column that’s missing from the data frame produced in the line of code right above.
- Trying to select from a table that doesn’t exist.
- Trying to call a function that doesn’t exist.
- Forgetting to include a required argument to a function.
- Trying to perform arithmetic on a string column.
When confronted with one of these Stupid Mistakes, fixing the problem is almost always trivial. We often discover these mistakes in one of a few ways:
- We manually test our code. Depending on the tools we’re using, this often requires deploying our code to a cluster, getting access to data, waiting a long time to chug through an actual dataset, and manually inspecting the outputs. However, some frameworks, such as Apache Spark, use the concept of lazy evaluation, which allows you to test the code without having to load and process the dataset (it still requires a cluster and access to the data).
- We deploy our code to production and catch the mistakes when the pipeline fails. I’ve been there, and I’m not here to judge you.
- We painstakingly write a unit test. This is What We Are Told To Do, but it’s often a waste of time. For transformations that operate on tables with many columns, most of the effort in writing the unit test goes into enumerating all the input and output columns, not verifying business logic. These tests then slow down further development because, when we want to make a small change, like pulling in a new column, we end up needing to change ten different sites in our code.
“Integration” Tests
What is quite challenging to test with unit tests is creating test cases that would answer questions like:
- Will my code work if the input data are malformed?
- What happens if the input data are not there yet?
- Does the app de-duplicate data in the proper way?
- Does the code properly infer the schema of CSV/JSON files?
- is the application idempotent? (do re-runs create the same output as one run?)
One solution to the challenges listed above is to focus not on unit testing, but on "external" testing of the application itself - running the application in the simulated environment and checking that the results match the expectations of the given test case. These tests are similar to integration tests in web services, where we simulate the client's input call and check how the state within the service changes and what result is returned to the user.
Read Integration tests of the Spark application to see an example of this type of testing using Spark.
Data Quality Assurance
As mentioned before, data quality tests can be used to check:
- source data, the quality or shape of which we rarely have any control over;
- data that is the result of our transformations. Yes, one way to test transformations is to make assumptions about the data set and then document those assumptions in the form of written tests.
In general, these tests can be divided into two groups:
- technical, focusing on the structural integrity and correctness of the data from a technical perspective;
- business-related, focusing on the relevance and accuracy of data in the context of business rules and processes.
Technical
They ensure that the data adheres to predefined rules and constraints. These tests typically include:
- Uniqueness Test: Ensures no duplicate values in key fields.
- Null Check: Verifies that fields meant to have data are not NULL.
- Data Type Validation: Ensures that data conforms to expected data types (e.g., date, integer).
- Range Check: Validates that numeric values fall within a specified range.
- Format Check: Checks if data follows a specific pattern or format (e.g., phone numbers).
- Foreign Key Constraint Check: Ensures referential integrity by verifying that foreign key values exist in the referenced table.
Because these tests verify the correct operation of data pipelines, they are the responsibility of data engineers.
Examples:
- Ensure that the primary key field customer_id in the customers table contains unique values with no duplicates:

- Verify that the email column in the users table doesn’t contain any NULL values:

- Confirm that the age column in the patients table contains values between 0 and 120:

- Validate that the phone_number column follows the format (XXX) XXX-XXXX:

Business
They ensure that the data supports business operations and decision-making. These tests typically include:
- Completeness Check: Ensures all necessary data fields contain values (e.g., every product has a category).
- Consistency Check: Validates that data is logically consistent within and across datasets (e.g., total amount matches the sum of item amounts).
- Timeliness Check: Confirms that data is current and relevant, adhering to time-related constraints (e.g., delivery dates within expected time frames).
- Accuracy Check: Ensures calculated values are correct (e.g., sales amount equals quantity multiplied by price).
- Referential Integrity Check: Validates relationships between datasets (e.g., all orders have valid customer IDs).
- Business Rule Validation: Ensures data adheres to specific business rules (e.g., discounts do not exceed a certain percentage).
QA engineers could be responsible for this type of testing, as it requires a good understanding of business needs and constant contact with data stakeholders and/or consumers. They could act as data stewards who manage data quality through continuous validation of business assumptions.
Examples:
- Verify that all products in the products table have a non-empty category fields:

- Ensure that the total_amount in the invoices table equals the sum of item_amount in the invoice_items table for each invoice:
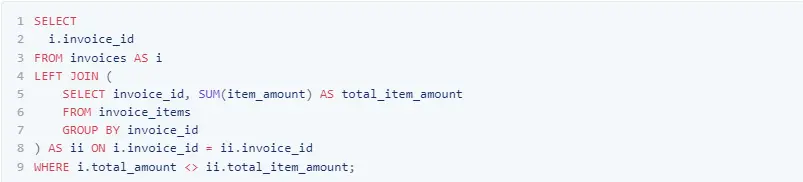
- Verify that the delivery_date in the orders table is within 7 days of the order_date:

- Ensure that the sales_amount in the sales table matches the quantity multiplied by price for each item:

- Validate that the discount in the sales table does not exceed 50% of the original_price:

When to Test Data?
Typically, we test the data after it has been transformed, i.e. after it has already been saved to the tables. But what if we want to run tests before this potentially faulty data is made available to end users, such as an application or analyst team?
The answer is to introduce a staging layer (tables). Instead of the following architecture:
.webp)
We could have:
.webp)
However, introducing an additional layer for testing, which is basically a copy of the next one, increases costs and lengthens the time it takes to deliver data to customers. After all, we do additional computations, need more storage space, etc.
Technologies
When it comes to running data quality tests, the days of writing custom frameworks that would run SQL queries, store the results in tables, and then send notifications to, say, Slack are (recently) long gone. Nowadays, several tools on the market allow us to quickly create tests by creating configuration files.
- dbt tests
Especially when combined with the calogica/dbt-expectations and dbt-labs/dbt-utils packages, which guarantee an impressive list of out-of-the-box tests, and elementary data for data observability and triggering notifications and alerts.
Docs: https://docs.getdbt.com/docs/build/data-tests - Soda
Similar functionality to dbt test, extended with the above-mentioned packages. dbt test is probably a natural choice if we are already using dbt to model the warehouse. If there is no need to use dbt, one can consider Soda.
Docs: https://docs.soda.io/soda/quick-start-sip.html
- Great Expectations
It's a powerful and extensible framework, but it has a steep learning curve. If your project involves complex data pipelines across multiple environments, requires extensive customization, or your team is not SQL-centric (think data scientists doing statistical quality checks in Python Jupiter notebooks), Great Expectations may be a better fit compared to dbt tests or Soda.
Docs: https://docs.greatexpectations.io/docs/
Additional Resources
Worth reading:






