

What is event sourcing?
Before we get into the technical aspects of event sourcing, let’s try to understand it in simple terms by using a practical example.
Mr. Joe Smith is a small business owner who isn’t quite tech-savvy. So, rather than using an online tool to track his business expenditures and income, he writes every transaction down in his journal as and when they are made.
At the end of the month, Joe receives his current balance statement from the bank, and he quickly recognizes that the calculations in the statement and his diary don’t match.
So, Joe quickly calls the bank helpline, and they send him a complete list of transactions he made through the account. As he goes through the list, comparing it with the record kept in his diary, Joe notices that he has missed noting down a couple of transactions.
The one thing we can take away from this story is that a bank always stores information about any changes that happen to an account in chronological order, starting with account creation. And the balance at any point is the outcome of all the transactions or changes. This, in simple words, is event sourcing.
The basic idea behind event sourcing as a coding practice is to store every change that happens to an application so as to capture its current state at any given point in time.
However, unlike traditional methods, event sourcing does things differently. It stores all data as a string of state-changing events. Meaning, when an object or entity is first added to the database, it serves as the first event in the string. Any changes that happen to this entity afterward are added as new events to the string as they happen. This makes it easier to describe a state change that occurred to the entity by replaying all the events in the order of occurrence.
One important thing to note here is that events are things that have already happened and hence cannot be changed.
Applications of event sourcing in Python
Now that you know what event sourcing is, it’s time to look at its use cases.
When people first hear about event sourcing, a lot of them assume that the practice is best suited for the finance industry. But seasoned programmers will tell you otherwise.
Beyond offering data storage and auditing capabilities to financial organizations, event sourcing has a wide array of applications across various sectors, including logistics, retail, finance, government, healthcare, and much more.
In simple words, event sourcing can be applied in all those cases where you have to store vast amounts of data and, at the same time, capture its state. For instance, tech companies can use event sourcing to perform an in-depth analysis of an expanding dataset to monitor the performance of their application or software solution.
Benefits of event sourcing in Python
Let’s try comparing the traditional data storage approach with event sourcing from a technological point of view to better understand the benefits of leveraging the latter.
Following the traditional approach, data is stored as objects. Meaning, a single command could affect several objects and only display their current state. In other words, a developer has to add new codes and integrations for additional tracking. Even so, only the details that occurred after adding the code are recorded, and anything that happened before that point is lost. This poses a serious challenge when working with complex and distributed software applications and systems.
On the other hand, event sourcing stores data as a string of events in an append-only log, recording any changes as they are made. This helps resolve consistency issues and problems with propagating the application state, as events could easily be circulated in the order they were executed.
The ability to view a complete history of the object state allows you to easily correct mistakes, rectify information loss, and debug codes.
Examples of event sourcing in Python
Now, let’s move on to some event sourcing examples in Python. Below, we will take a step-by-step look at how to create an event, make changes to it, save it to a repository, and retrieve it.
Event-driven persistence layer
We will keep this simple by creating a base class with a producer_id and an AccountCreated event with a deposit, as shown below.
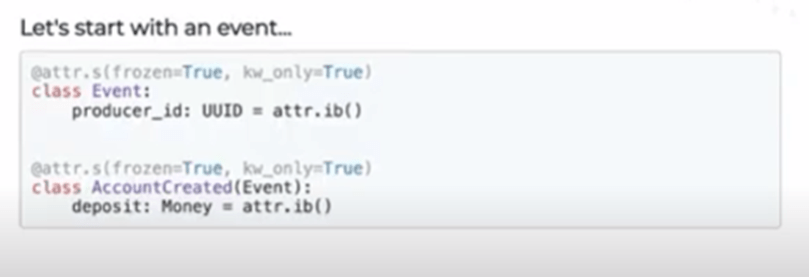
To achieve this, we could pass the AccountCreated event as a list or a sequence. However, it isn’t quite idiomatic because it doesn’t look like Python. Python is a simple and user-friendly language, while this looks rather unfamiliar.
In Python, we do something like this:
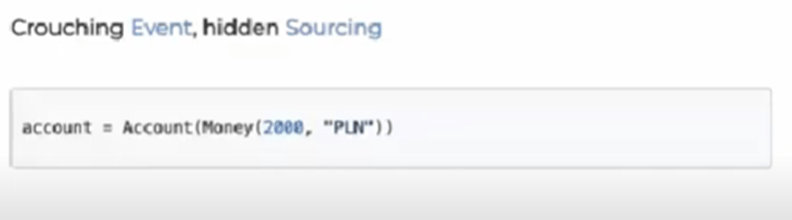
However, the bad news is that it is hard to get rid of that complexity, because it is the root of event sourcing. Nevertheless, the good news is that you can choose to hide it—we can shuffle the complexity from place to place.
Here is one way to hide that complexity:
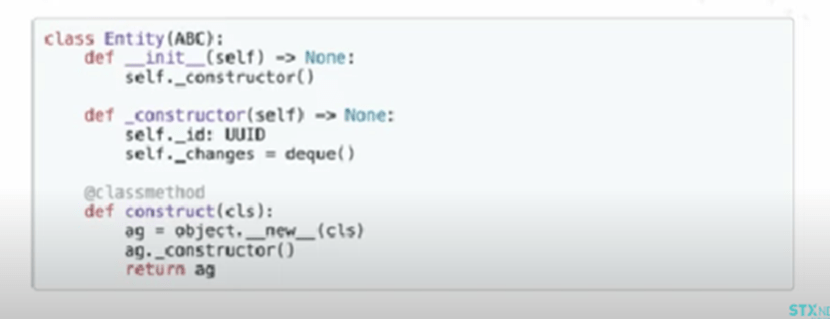
And yet, it still looks quite complicated. So, let’s look at another method to achieve the same results.
Retrieving state with SQL and ORM
This method is quite simple and can be done in two steps:
- Step #1: Select a record from a database
- Step #2: Feed the values to the (only) constructor
And you’re done!
In principle, this is how it works.
Unfortunately, it gets a bit tricky with event sourcing.
Retrieving state from an event store
- Step #1: Create an empty shell of an entity without emitting any events. We stress the “without emitting any events” part, as it is crucial to avoid a situation where you have several AccountCreated events because you retrieved them from an event store.
- Step #2: We get the event’s history, preferably as a generator, from the underlying event store for the given ID of our entity or aggregate.
- Step #3: Apply that sequence of events on that empty shell and fold it, starting with the Create event.
The great thing about this method is that we can stop at an arbitrary point in time. Meaning, we can very easily bring our system to a state we believe was the cause of a particular problem. Now, in principle, we can do that with versioning, too. But the problem is that there is a limit to versioning, as it doesn’t really tell you where that state came from.
While you can store information, versioning acts like a log and only tells you what the state was like in the past and not where it came from. But events with different event types do that.
Two cases, two constructors
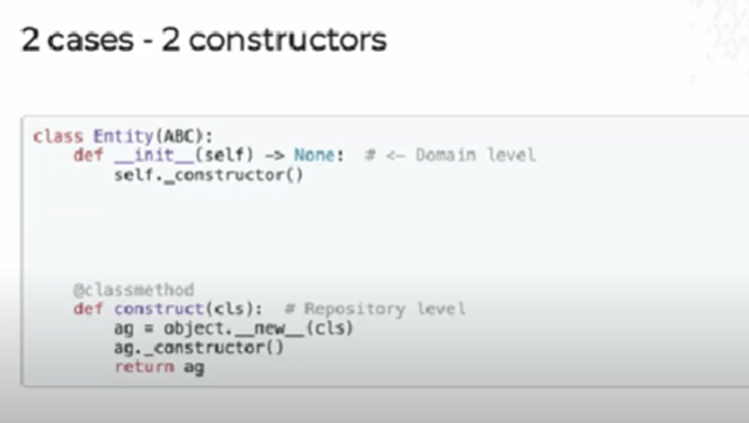
In the image above, we have two cases and two constructors:
- The constructor for the domain logic
- The repository-level constructor
While the first constructor looks like every other constructor, the second one is peculiar and works differently. Nonetheless, one thing that both constructors have in common is that there are things that have to be created no matter where the entity originates.
Case #1: Idiomatic creation
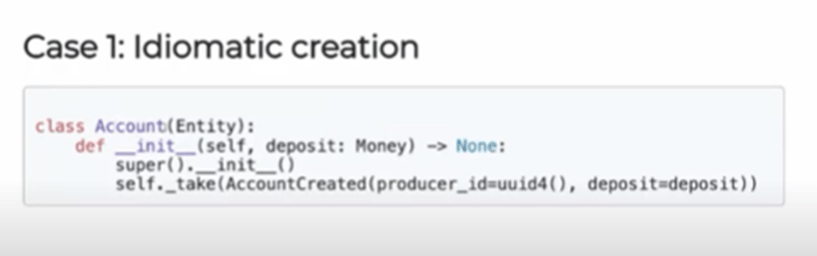
In the idiomatic creation of an account, you can see an Account class, run __init__() from the parent class, and an event. However, here the event handling is hidden underneath the layer of the account and inside the class.
Case #2: Retrieval
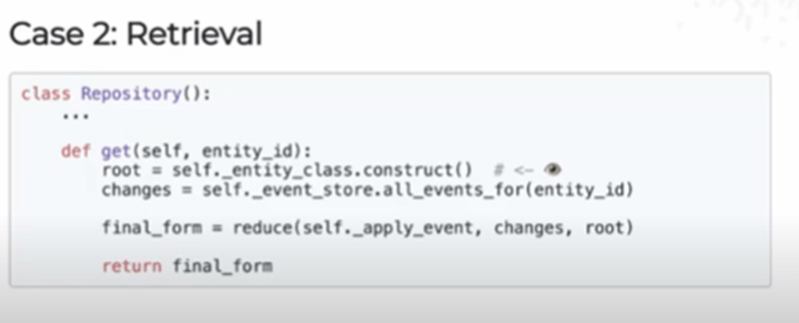
Here, on the other hand, our repository looks like a sequence of events or calls of happenings.
We begin by creating a root, an empty shell of an entity, grab all of our changes and apply all of those changes onto that root to get the final form of an entity.
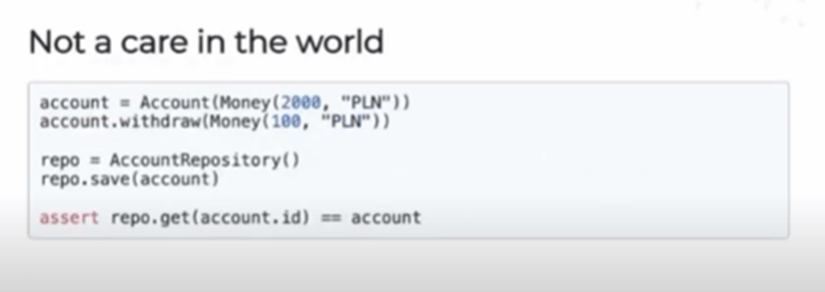
Our domain logic is oblivious. It looks like every other hexagonal or clean architecture—there is a repository pattern, entities, and methods on the entities to perform operations on them.
Now, take a look at this relatively simple code below:
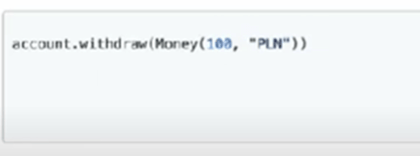
Can you tell what secrets this code may be hiding below its surface?
Well, check out this image now:
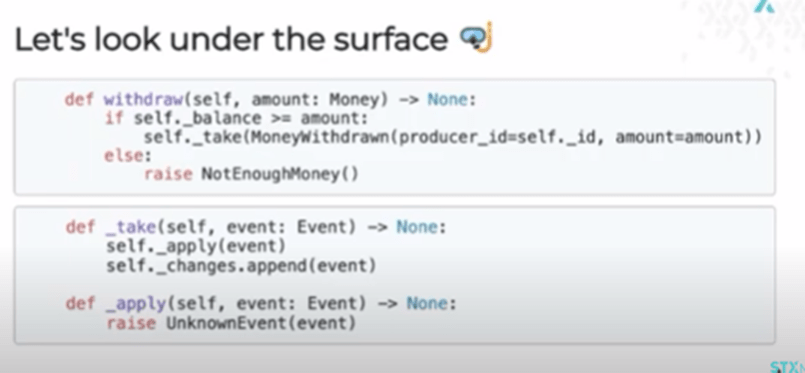
Underneath the surface of this event handling bit, three layers are deliberately separated, because one of those blocks lives in the entity parent class, while the others live in the account class.
At the core, we have withdraw, at which level we perform validation—ensuring you have enough money. This is done by creating an event, taking the event to the entity that applies, and adding it to the history.
But there are actually three terms, or layers, of importance here—withdraw, take, and apply:
- withdraw—Validates, raises exceptions, calls external services, etc. Everything we don’t want happening at the repo.get () level is done at this layer to avoid exceptions being raised for the wrong reasons every time we get something from the repository.
- take—Acts like a wrapper that helps add data to the history for new events and handle some event-agnostic tasks.
- apply—Implements the actual change in response to a particular event and uses some Python that isn’t as commonly used as it could be, which is single dispatch.

An important point to remember here is that there is always one apply with numerous implementations that are selected based on the event class and passed into the original apply. This is a great way to avoid the vast dictionary that comes with event class handlers if a single dispatch isn’t used.
Saving the event and all the changes made
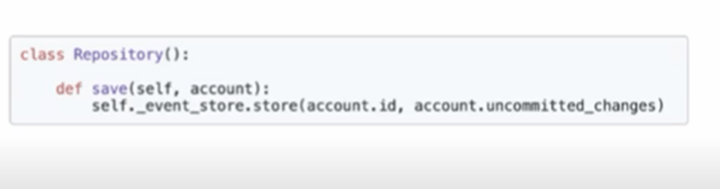
You can see a repository in the image above. All that needs to be done to save your work is to get your event store, call a function and a method on it, then pass the account.id or the ID of the entity and any uncommitted changes that are new since we last created or retrieved this entity from the repository.
And you’re done!
But that’s not at all—far from it, in fact. We strongly encourage you to watch Piotr’s whole webinar here to learn about real-life problems with event sourcing and their solutions in Python.
Final thoughts on event sourcing in Python
Event sourcing is gaining wide acceptance within the industry, since an increasing number of applications today need real-time data in chronological order to function efficiently.
As mentioned earlier, an event source acts as a common point of truth for applications, regardless of how data is processed or supplied by the application. Therefore, it is a great way to manage the applications’ log data on a web-scale.
However, we understand it might not be easy to juggle event sourcing when you’re relatively new to the practice. That’s why we hope this guide on how to perform event sourcing with Python will help you handle operations on data driven by a sequence of events.
Thank you for reading our article! If you found it useful and would like to check out more similar content, consider going through the following resources on our website:
- Python vs. Other Programming Languages
- What Is Python Used for?
- How to Audit the Quality of Your Python Code: Checklist and Sample Report
- The Best Python IDEs and Code Editors (According to Our Developers and the Python Community)
- 40 Most Popular Python Scientific Libraries
- Python 2.7 to 3.X Migration Guide: How to Port from Python 2 to Python 3
- Python for Data Engineering: Why Do Data Engineers Use Python?
Also, feel free to reach out to us should you wish to receive software development assistance of any kind. Take a look at the services we provide to see if we could support you in some way if you’re looking to extend your engineering team or have other project needs!






